If you’re searching for Linux backup solutions, we commend you for taking seriously an area that many organizations neglect. Just about every business has methods of backing up at least some of its data, and many have a means of restoring business applications after a system outage. But if you’re considering backing up on a wider scale rather than simply copying what you consider to be your most important files, you’re obviously willing to give your organization a higher level of protection.
The question remains: what should that protection be? That’s not a question we can answer in a few paragraphs because it depends on where your Linux servers are located, how quickly you want to be able to restore your systems after a crash, and how much of an investment you’re willing to make in Linux backup solutions (hint: you need not break the bank, but freeware probably won’t cut it, either).
Let’s get started.
Part One: Where Are Your Servers?
You can’t find the right Linux backup solution until you’ve thought about where your Linux servers are located. They’re probably either in a third-party data center (co-location) or in a server room on your company’s property (on-premises).
Third-party data centers come in several flavors. Some data center providers provide rack space in a data center but leave you responsible for maintaining your servers. Other vendors provide a full range of services, such as backups and monitoring.
And then there are cloud data centers (often called “infrastructure as a service,” or IaaS). Some IaaS providers offer full service. Others (including Amazon) simply offer the servers but leave you to maintain them.
The truth is, most organizations have a mixture of all of the above. Companies will probably always find a need to manage some of their own servers, whether those servers are down the hall or in a data center in the next state. And despite all the buzz that cloud computing has received in recent years, a 2019 survey revealed that 98 percent of companies still had at least some on-premises servers. Having boxes in-house continues to appeal to CIOs who want to protect themselves from cloud vendors who may raise prices, change terms of service, or simply go out of business and leave customers scrambling. A capable IT team can maintain a server in-house quite cost-effectively. And some executives would prefer the capital expenditure of a server purchase to the operating expenditure of a cloud server.
“There is a fairly significant amount of repatriation going on,” said Michael Dell, in an interview with CRN. “As much as 80 percent of the customers across all segments – small, medium, large – are reporting that they’re repatriating workloads back to on-premise systems because of cost, performance and security.” ¹
Part Two: Backups Are Still Necessary
If it’s fair to assume that businesses will always have some physical servers, then it’s also fair to assume that most—if not all—businesses will tap into the cloud for at least some of their computing power. In fact, the trend is towards more cloud servers and fewer physical ones. But as companies increasingly embrace the cloud, a dangerous myth is emerging—one that says the need for backups is disappearing along with the company server room.
Nothing could be further from the truth. As long as your company has mission-critical applications that cost you thousands of dollars for every hour they stay down, and as long as you have irreplaceable data, you’ll need backups.
But as we will soon explore, not all backups are created equal. If you’re backing up all your mission-critical servers to the cloud but it would take 10 hours to restore them, you don’t have a solution—you have a potential problem. If your cloud provider has all the control over your applications and data, how long will it take you to restore that backup on premises at your company? The answer to this question can make or break your Linux backup strategy.
“Remember that the cloud service you use, whether it is IaaS, PaaS, or SaaS, is just another data center like one you might build yourself—only it’s in another place run by other people. They may be the best at what they do, but neither they nor the systems they employ are infallible. That is why you should always have backup and disaster-recovery plans in place. Hope you never have to use them, but have them ready if you do,” says W. Curtis Preston, Chief Technical Evangelist at Druva. ²
Now, how does cloud repatriation change the picture? This is a new trend in which some companies are moving their cloud workloads back to on-premises servers. Cloud repatriation doesn’t indicate a permanent shift away from cloud resources—indeed, there are many reasons companies may choose to take some of their resources back in-house, and many do so only temporarily. But as companies move workloads freely to and from the cloud, the need for a comprehensive, flexible Linux backup strategy only becomes more urgent.
Part Three: Best Practices for Linux Backup
In a sense, there’s only one best practice for Linux backup: back up your business environment in such a way that you can restore data and applications in minutes, not hours. Of course, designing such a plan is the difficult part. In the process, system administrators often make one or more critical oversights or mistakes. For that reason, it may be most helpful to express best practices in terms of what not to do.
Here are several Linux backup mistakes that can threaten the health of your business:
- Not backing up the operating system. Most companies focus on backing up their data—and with good reason. Losing your entire customer database, for example, would be devastating. Some companies also back up applications. But few back up the OS. They figure it’s not worth the effort. With OS disks readily available, it doesn’t seem like such a burdensome task to reinstall the OS after a crash.
Although installing an operating system may not take long, think of all the updates and customizations you’ve made to your OS since the original installation. If your OS is completely wiped out by a disaster, you would not only have to provision a new base OS, but also install a series of patches and updates to get to the same state before the failure. That process can take several hours. Add those hours on to all the other tasks involved with disaster recovery, and you could be costing your business thousands of dollars in lost revenue.
- Making image-based backups. Image-based Linux backups sound like a great idea. They allow you to restore from a mere snapshot of your system. But they have a catch: you must restore onto exactly the same hardware.
That may not sound like a big issue. But think about how often hardware vendors make slight changes to their servers. If one of your servers is completely wiped out and you’re forced to restore onto a new box, you don’t want to have to search eBay for a discontinued server model. That’s why making image-based backups is a short-sighted strategy.
- Making snapshot backups. Some system administrators see virtual machine (VM) snapshots as a good backup solution. In theory, they’re a great solution: they take an image of the entire virtual machine and allow you to restore onto new hardware.
In practice, though, VM snapshots have a significant weakness: they’re all-or-nothing. It’s extremely challenging—some would say nearly impossible—to select the exact files you want to restore after a disaster. If that disaster was malware-related, then you’re going to be in a bind: you could end up restoring malicious files onto a clean new server and perpetuating the problem you were trying to solve.
VM snapshots have their place in day-to-day system maintenance. But we say they’re not a flexible enough Linux backup solution for disaster recovery.
- Discontinuing disaster recovery drills after moving data to the cloud. As wonderful as the cloud is, it can lull system administrators into a false sense of security. They get a vague sense that even if the unthinkable happens to their applications and data, they’ll simply be able to log in and restore everything.
But if you’ve handed over control of your applications and data to your cloud provider, keep in mind that after a disaster, your access will be on your vendor’s terms, not your own. Your disaster recovery plan should take this into account as you plan your restore time objective (RTO) and recovery point objective (RPO). And you should continue to conduct disaster recovery drills that verify how realistic your RTO and RPO really are.
The ideal Linux backup strategy will revolve around a solution that can perform full-system backups—and it will call for you to conduct disaster recovery drills just as often as you did before you started moving your data and applications to the cloud.
“In some cases, keeping certain backup or disaster recovery processes on-premises can help you retrieve data and recover IT services rapidly. Retaining some sensitive data on premises might also seem appealing if you need to comply with strict data privacy or data sovereignty regulations,” says IBM. ³
Part Four: Overview of Linux Backup Solutions
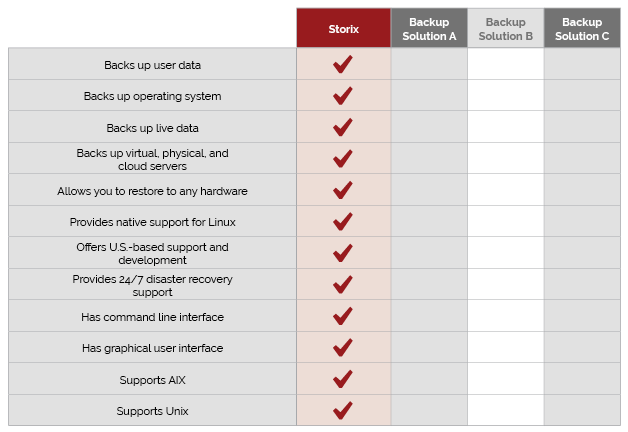
As you consider possible Linux backup solutions, you have no shortage of options. However, here’s a scorecard with services to consider as you shop around:
Conclusion
It’s a crowded market for Linux backup solutions. But don’t make the mistake of thinking that one solution is as good as the next—or that a freeware solution deserves consideration simply because it won’t increase your IT budget.
To ensure that your business can meet its RTO and RPO, you need a full-system backup solution that enables you to restore to any hardware in minutes—not hours or days. Storix SBAdmin is that solution.
As we mentioned above, Storix only backs up Linux, Unix, AIX, and Solaris. But it provides the highest level of protection for these systems. So, if your organization is also running Windows or Mac servers, we believe you should implement Storix for Linux and a separate solution for Windows and Mac.
See why Honda, CVS, Kohl’s, Lockhead Martin, McKesson, Bridgestone and other leading companies rely on Storix for their Linux backup needs.
¹ https://www.crn.com/news/data-center/michael-dell-it-s-prime-time-for-public-cloud-repatriation
² https://www.networkworld.com/article/3615678/backup-lessons-from-a-cloud-storage-disaster.html
³ https://www.ibm.com/cloud/learn/backup-disaster-recovery#toc-dont-wait–HyEmAQNh